
Six years ago, in response to a Knight Foundation challenge program, we put in a proposal entitled “10,000 Creative Commons Ebooks”. We had compiled a list of 2,300 Creative Commons Licensed ebooks, and we thought that with some more resources we could identify as many as eight thousand more. We didn’t get the grant, but we kept on adding free ebooks to the Unglue.it catalog using automated processes and by individual discernment. We added Public Domain ebooks from Project Gutenberg, over 60,000 of them. We added over 30,000 Creative Commons licensed books from the Directory of Open Access books. We added computer books and textbooks, about 5,000 total. By the end of 2021, we had 102,692 open access books in our catalog and had distributed 6.45 million ebooks.
Along the way, we’ve been able to help our not-for-profit peers (Project Gutenberg, DOAB, etc.) improve their software, processes and metadata in small ways and big ways. There’s still a lot of work to be done. Our search facility could be 10x faster and smarter. We need to figure out how to make the collection more useful, by curation, by cataloguing, and by distribution ( by “we” I mean our community as a whole!).
2022 could be exciting in so many ways.
Crowdfunding Monographs
This week, we released our first monograph crowdfunded into Open Access with the assistance of the Free Ebook Foundation Open Access Monograph Fund . As part of an ungluing campaign, the publisher of Mark G. Bilby’s “As the Bandit Will I Confess You” agreed to release it under a Creative Commons license. We’re thrilled to be the catalyst to make this happen.

Stats
Unglue.it free ebooks by format:
pdf: 102,287
epub: 73,241
mobi: 71,757
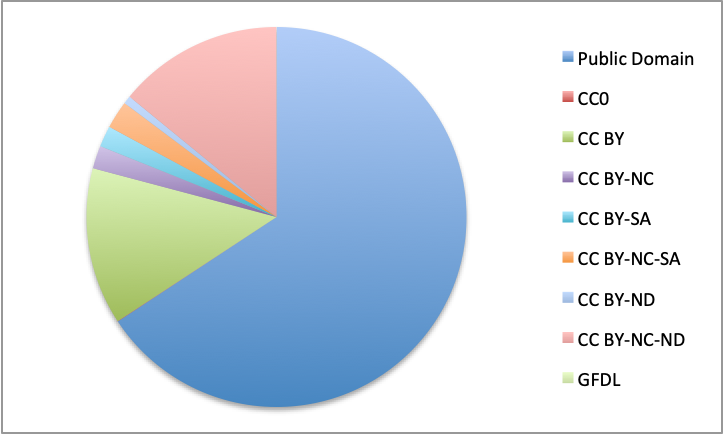
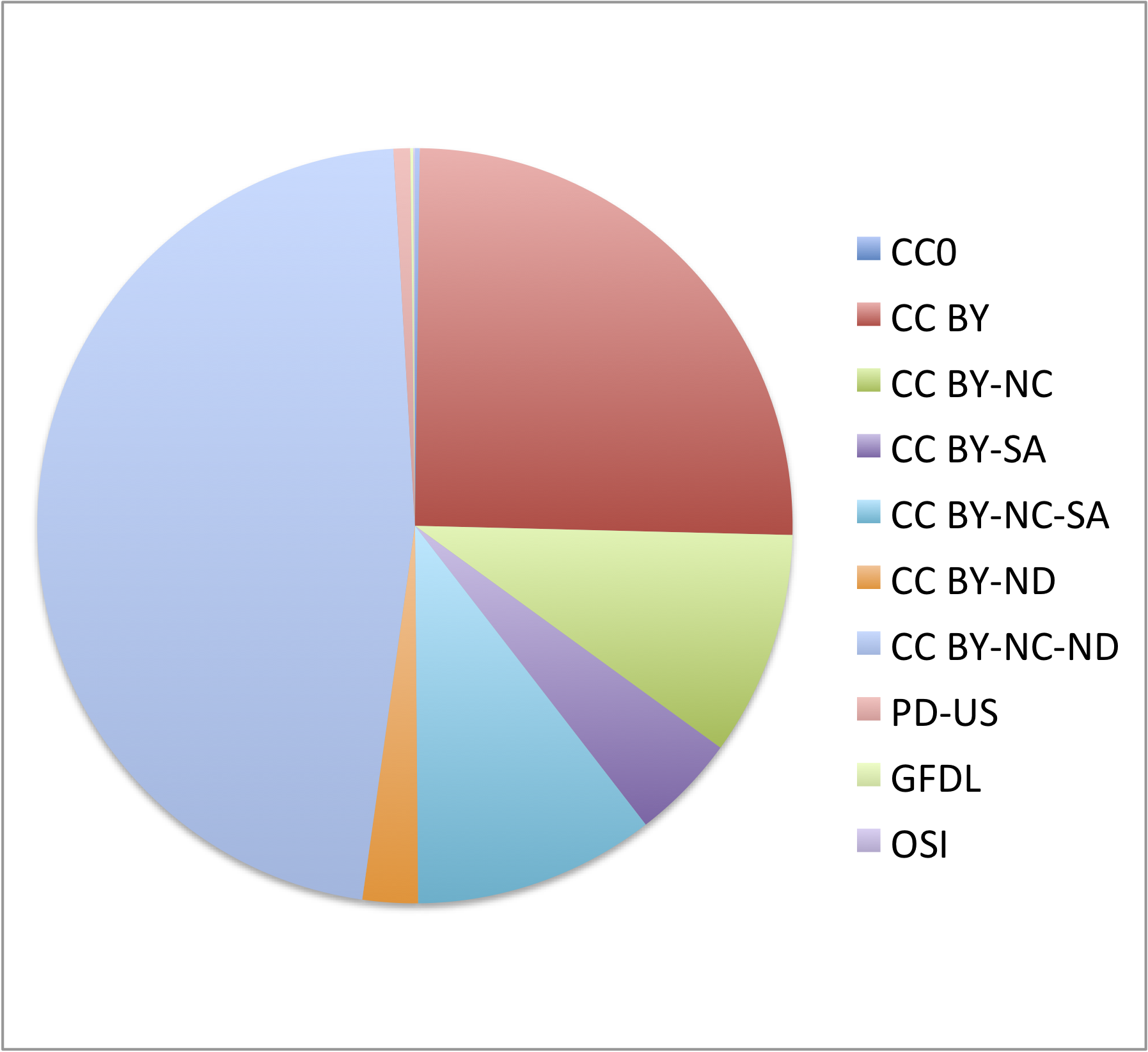
Unglue.it free ebooks by license
Public Domain 65102
CC0 33
CC BY 13239
CC BY-NC 1928
CC BY-SA 1771
CC BY-NC-SA 2344
CC BY-ND 676
CC BY-NC-ND 13928
GFDL 15

 Over the past month, the Free Ebook Foundation’s
Over the past month, the Free Ebook Foundation’s  But imagine being poet Janet Hujon, who grew up in Shillong, the capital of the Meghalaya state in eastern India. She lives in England, where most folks, like us, probably haven’t heard of Khasi, Shillong, OR Maghalaya. She writes in English, but the stories she heard as a child continue to fire her imagination and the Khasi culture, as embodied in the poetry of Soso Tham, form the foundation of her world view and literary work. It must frustrate her that Soso Tham’s poetry is inaccessible to the English speaking world.
But imagine being poet Janet Hujon, who grew up in Shillong, the capital of the Meghalaya state in eastern India. She lives in England, where most folks, like us, probably haven’t heard of Khasi, Shillong, OR Maghalaya. She writes in English, but the stories she heard as a child continue to fire her imagination and the Khasi culture, as embodied in the poetry of Soso Tham, form the foundation of her world view and literary work. It must frustrate her that Soso Tham’s poetry is inaccessible to the English speaking world.
